![]()
Cataloger's Reference Shelf
MARC 21 Format for Classification Data
![]()
Cataloger's Reference Shelf
MARC 21 Format for Classification Data
Model A - Vernacular and Transliteration (Appendix C: Multiscript Records)
 Example
1:
Example
1:
The following example of a multiscript record follows Model A. In this example, field 153 is expressed in both Cyrillic and Latin scripts.
040 ## $a***$brus$c***
084 0# $alcc [Library of Congress Classification]
153 ##
$6880-01$aHA1$cHA4737$j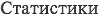
880 ## $6153-01/(B$aHA1$cHA4737$jStatistics
![]()
Example
2:
The following example of a multiscript record follows Model A. In this example, field 153 is expressed in both Hebrew and Latin scripts. Note that the second 880 field is not linked to an associated field. The occurrence number here is 00.
The directionality of the Hebrew text in the examples is right-to-left within each subfield, but the subfields themselves have been recorded left-to-right. The actual input of all the data is in logical order (first-to-last), parts of which may be displayed in various directions depending upon the script and the display interface.
084 0# $alcc [Library of Congress Classification]
153 ## $6880-01$aPR1588$hEnglish literature$hAnglo-Saxon literature$hIndividual authors and works$hBeowulf$hCriticism$jLanguage, grammar, etc.
730 00 $aBeowulf$xLanguage$0(DLC)sh#85013267#
880 ## $6153-01/(2/r$a<Caption in Hebrew script linked to associated field>
880 ## $6680-00/(2/r$a<Scope note in Hebrew script>
See also: